

With the rising trend of more and more people using Supabase as a backend for WeWeb, rises also the amount of people who come to me to consult about certain issues regarding this set-up. In these WeWeb examples, I’m bringing a comprehensive guide or a decent knowledge-base regarding a more in-depth usage of Supabase in combination with WeWeb through comprehensive.
A few words about Supabase, and why you should use it in your low-code project
As most of you reading this might already know, Supabase is a very handy open-source alternative to Firebase which also is an interesting BaaS, which I wrote about in the previous post.
Supabase provides all the backend services you need to build a scalable WeWeb application – supafast. I also usually go as far as calling it the Xano alternative for the more brave ones. With its real-time capabilities, PostgreSQL database, authentication, and storage solutions, Supabase is perfect for I think anyone, who wants to build applications quickly without managing complex backend infrastructure. Its seamless integration with WeWeb, has been allowing me and many others to build heavy duty, scalable apps in no time.
What I mostly like about Supabase, is the freedom of choice that it gives you, which is why I suggest it to almost anyone, who is down to go the low-code path, and get their hands a little dirty with SQL in exchange for big rewards in terms of productivity, scalability and developer experience as a whole.
Fetching the data effectively is vital for your app
Data is the lifeblood of any application. Unless you’re creating a simple calculator of course, It’s crucial to understand your data. As we discussed last time, fetching data is just as important as knowing your data characteristics, such as types. The WeWeb’s Supabase plugin offers you many ways to fetch the data, in the next paragraphs, I’ll go over them in a little more depth.
The good old WeWeb collections
The most established pattern to fetch data with Supabase, or with really any other backend / REST source, is through the WeWeb’s Collections – these are super handy in 90% of the cases, and I build with collection-first mindset.
The static pages problem
Unfortunately, Supabase collections don’t support Static Collections, which are used for creating Static Pages in WeWeb. However, I found a neat workaround to make it work. You can use a feature of Supabase that creates a REST API around your schema (tables, functions, and views). The REST Plugin in WeWeb allows us to fetch data from a REST endpoint, and since it supports Static Collections, this is all we need.
The only downside is that this approach is a bit more technically complex. However, if you’re reading this, I have no doubt you can make it work. You can find your API credentials in your Supabase Dashboard, and the necessary tokens in WeWeb’s user object once you’ve installed Supabase Auth, assuming you’re protecting your database.
The new kids around the block – WeWeb workflow actions
In January of this year, after an intense wait got a major update to the WeWeb Supabase Plugin, which also introduced the version 2 of the Supabase SDK. This not only bettered the developer experience, but also introduced supercharged workflow actions that come with the WeWeb Supabase Plugin. Among the most marcant changes were the following
| Storage Bucket Actions | Enabled the access to the Supabase Storage Buckets for downloads, uploads and much more. |
| Ability to call Postgres Functions and the Supabase Edge Functions | This enabled us, to effortlessly call any of the PostgreSQL stored procedures or Supabase Edge Functions, which before required calling them the via the before mentioned REST API. |
| Advanced filtering and JOINs | Which opened broader possibilities for selecting the data supa-efficiently from the frontend. |
Joining the data effortlessly in WeWeb
The majority of the WeWeb users (me a few months ago before learning this included), don’t know how to fetch their Supabase data in an efficient and effortless way. This feature of WeWeb’s Supabase plugin, almost feels like magic. I’m talking about Advanced data embedding, or simply called JOINs.
What are the JOINs and why you should use them
Imagine we have our Supabase backend, that has two tables, containing related details about the products of our online marketplace, a very familiar pattern. For the purpose of these WeWeb examples, we’ll have a table products which will contain our clothing items, and a table called brands, each product can have a brand – so far so good, right? Among the people I know (and me) there are two types of approaches WeWeb-ers take.
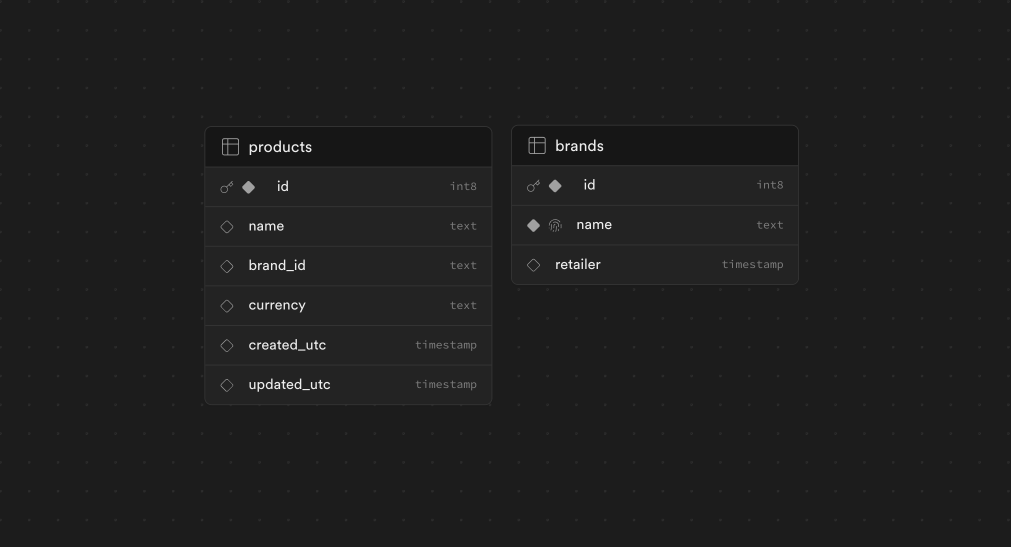
Merging the data in the frontend
This first case, is a very common one, you fetch your data in two different collections, you get the two and you merge them on the frontend via a lookup function. While this is a great way of doing this, especially when you’re a no-coder who just wants to get the job done, or when JOINs aren’t an option.
Join the data in the backend
Creating backend Stored Procedures (and views) for is my preferred way of doing this, when things get complex, it allows me to create a Xano-like endpoint, where I can accept parameters, call other business logic, and manipulate the data. It is really sturdy and the only disadvantage really might be the maintenance, and some higher effort required to write the procedures and views.
We actually can get the best of both worlds
What if I told you, that you could do 75% of your backend joins, or frontend lookups on the frontend, by writing simple logical queries, while mantaining the backend foreign key relationship join functionality? That’s exactly what the first of today’s WeWeb examples is about. The way it works is that you can define JOINs in the front-end via a specific syntax inserted into the Advanced tab when selecting your columns.
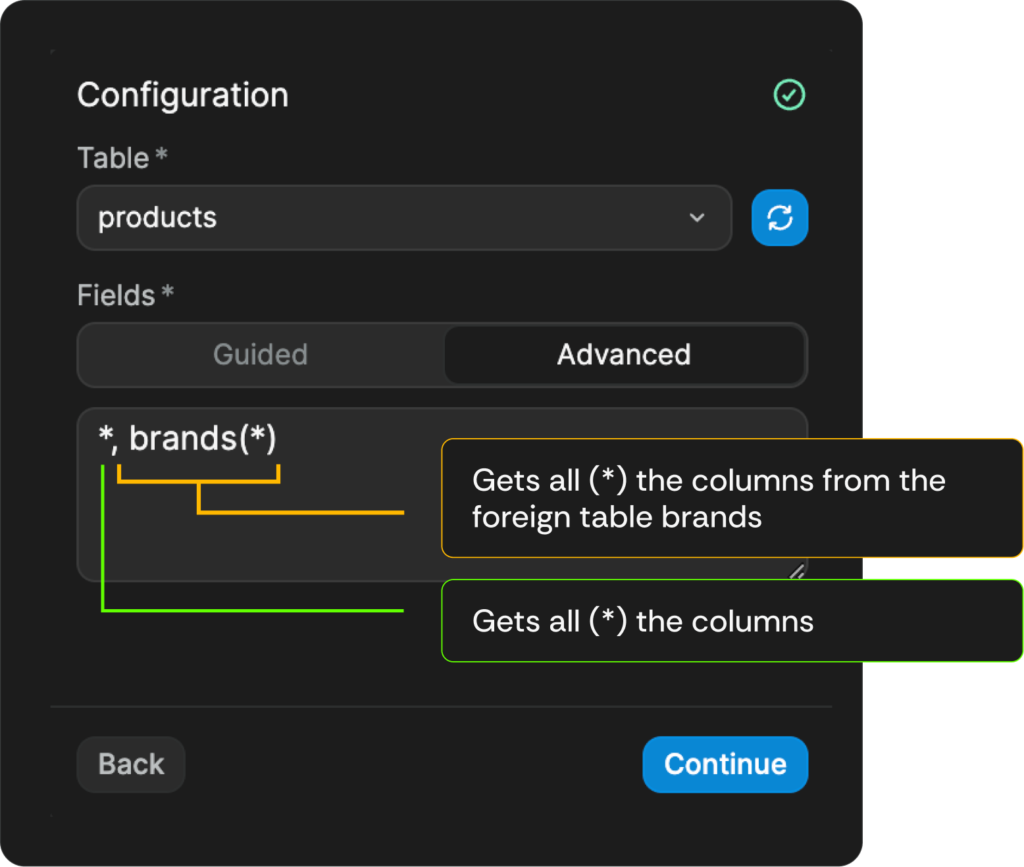
Inner JOIN type for matching records in both tables
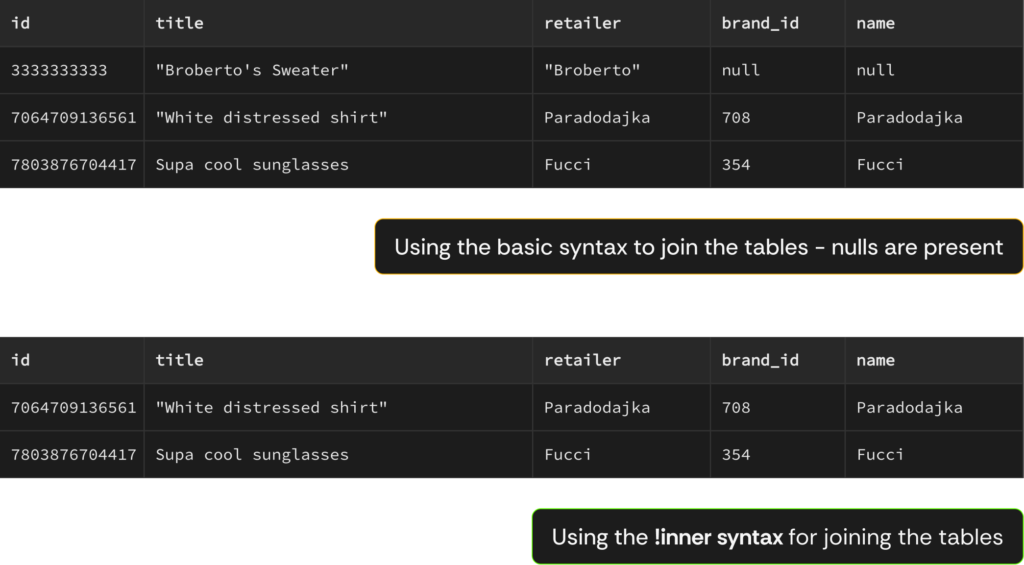
Sometimes you might want to get in your results only the records that have matching records in both tables, I think it will be simpler to illustrate on our clothing marketplace WeWeb example app. In this case, we would only want to fetch the products joined to brands, if the corresponding brand exists. If the corresponding brand doesn’t exist, we simply don’t fetch the product either.
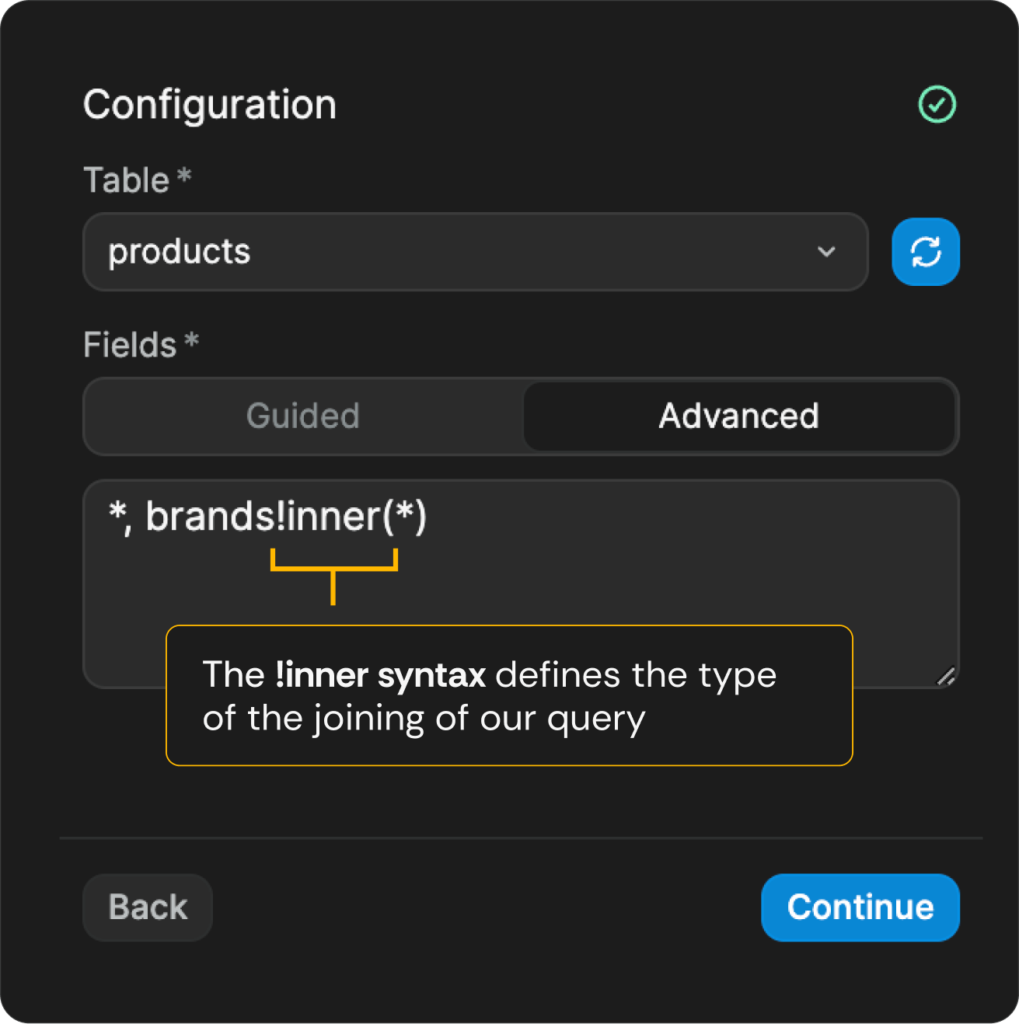
In the case of the above query, the results could look like the following data. We can clearly see, that when writing the query without the !inner syntax, we get all the products, no matter if it has a corresponding record in the brands table (brand_id is not null). In the second query, when using the !inner syntax, we get only the records (products) that have a matching brand record.
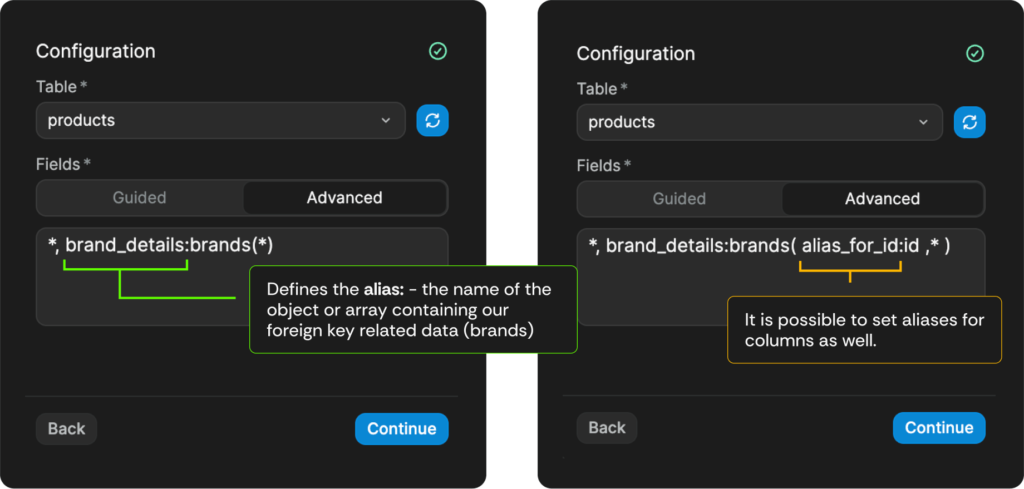
Aliases for more flexiblity in our data
If for some reason, you need more flexibility in the naming of the columns, and the joined data groups, we can use the aliases in our query like in the following WeWeb examples.
This allows us to set our own names – aliases – like in Postgres directly from the WeWeb’s Supabase plugin. This allows us to match flexibly the data types of our app, without having to change anything on the frontend, as we can manipulate the data from the query to match any structure that is already present.
Simplifying the data structure via spreading it
As we already saw in the previous WeWeb examples, the Advanced data tab in the WeWeb’s Supabase plugin is quite powerful. We’re able to fetch the foreign key related tables with ease, which is great, but sometimes, it can bring some over-complexity into the resulting output data.
{
"id": 1,
"name": "Distressed sweater",
"brand_id": 33,
// brand.id is redundant and the columns are nested
"brand_details": {
"id": 33,
"retailer": "Broski's Sweaters"
}
}Sometimes, you just want to have the joined data from the foreign table, at the same level, to avoid over-complexity when working with it later on. This usually happens with a Many-to-One or One-to-One relationships, where there is no need to wrap the result in an array, as it’s secured to be only one item. By default, all the joined tables we get from or queries, are arrays containing the (joined) objects.
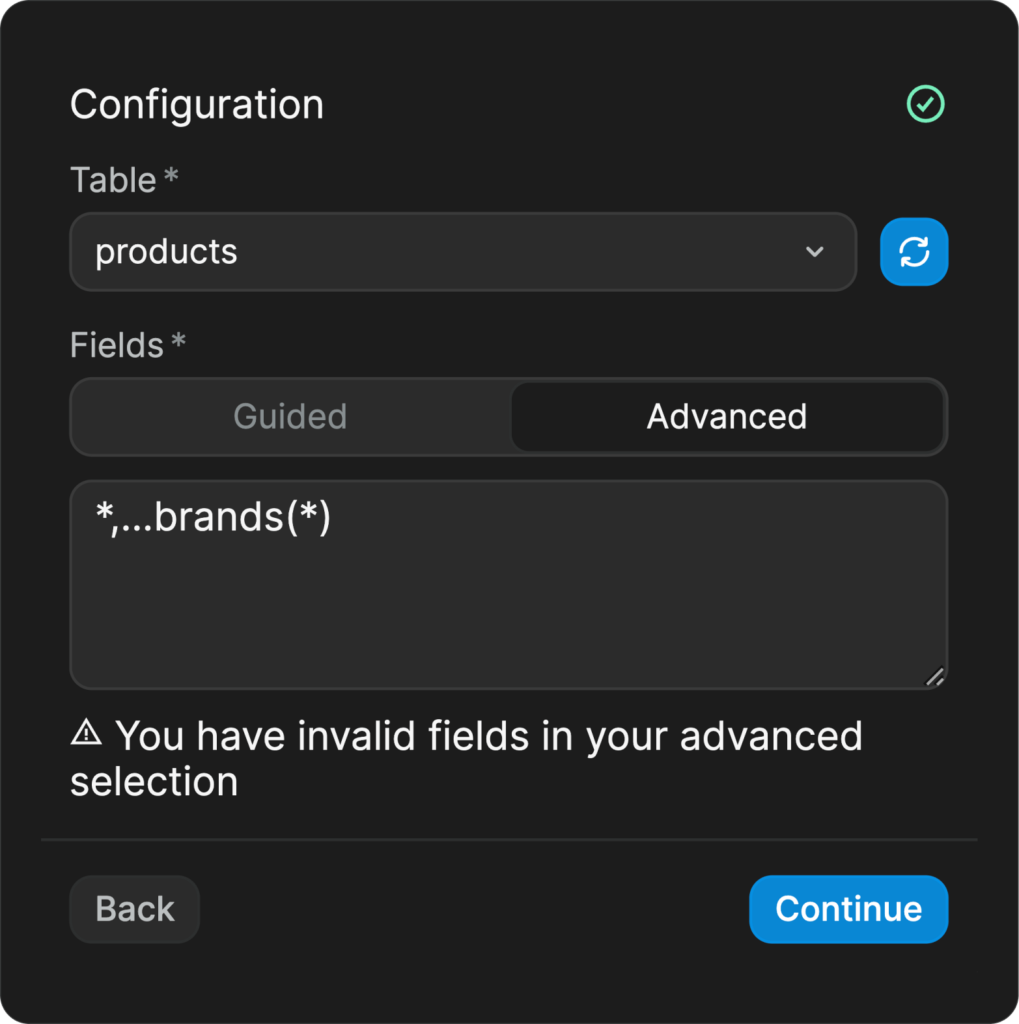
We can solve this by using the ... spread operator syntax to “spread” the foreign table into the main object – this can be seen in before the brands(*) in the example above. This allows us to simplify the query to something that looks like the following data supa-easily and we not only avoided the unnecessary complexity, but also the repetitions as the brand_id was present twice in our data before spreading it, which is a little redundant.
{
"id": 1,
"name": "Distressed sweater",
"brand_id": 33,
// brand.id is gone and the retailer is on the same level
"retailer": "Broski's Sweaters"
}Supa-efficient data filtering of the joined data
One of the new possibilities that the WeWeb’s update to their Supabase plugin brought, is the ability to filter by “nested” fields. This means that you can filter by foreign key values, that are nested in the arrays and objects – generated by the above mentioned JOINs.
Let’s say, that we want to filter our products, which we assigned a brand to via a foreign key relationship above. We will be filtering them based on a few conditions:
- The
brand_namecontains our search parameter - The brand is not null – the
productactually has a brand assigned
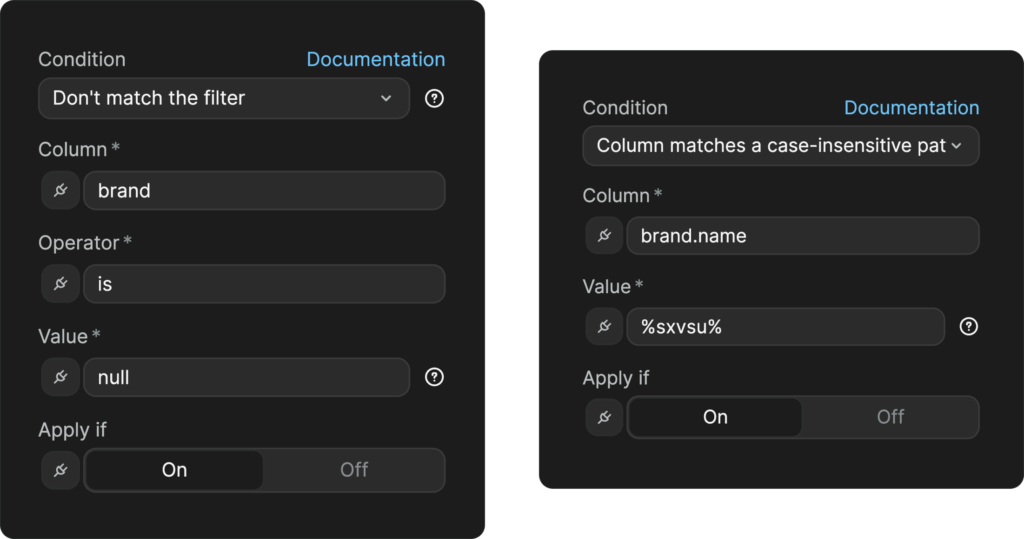
The brand_name contains our search parameter
For illustration purposes, I didn’t bind the value, so everyone can see well what goes into this filter. It’s fairly simple, we are going to be “Matching a case-insensitive pattern”, which in simple terms means, we’re gonna match a piece of a string. In this case, we need to wrap the %variable% in percentage signs, it’s the syntax that represents the “wildcard”, e.g match anything before, and after this.
You can see, that the syntax to access the “nested” values from the foreign JOINs is as simple as the syntax for the filter. We can use the dot.notation, to access nested values in our query.
The brand is bot null – the product actually has a brand assigned
In this case we haven’t used the inner join to filter out products without a brand. This caused that we have products where our brand object or array can be null entirely, meaning that the foreign key relationed record for this current product record doesn’t exist at all. We can access the object as well directly inputting brand (our alias for the brands JOIN) in the column of our filter.
The most important thing to become a Supabase magician – the practice
As you can see in the previous WeWeb examples, integrating WeWeb with Supabase opens up a plethora of opportunities to build efficient, scalable, and dynamic applications. The advanced capabilities provided by both platforms, when combined, offer a robust framework that can handle complex data structures and workflows with ease.
As with any skill, practice is crucial to mastering Supabase and WeWeb. The more you experiment and build, the more comfortable you’ll become with their features and capabilities. What I can suggest to you all, is – use these WeWeb examples, the extensive documentation and community resources available for both platforms to troubleshoot issues and share knowledge.
Whether you’re a seasoned developer or a low-code enthusiast, understanding how to leverage these tools effectively can significantly enhance your productivity and the quality of your applications.
For those just starting out, don’t be intimidated. The learning curve is well worth it, and the productivity gains you’ll experience are substantial.
I hope these WeWeb examples have provided you with a solid foundation for fetching data with Supabase in WeWeb. If you have any questions or need further assistance, feel free to reach out. And happy building!
